

Gobobby
TopCoach MASTER
Workshop
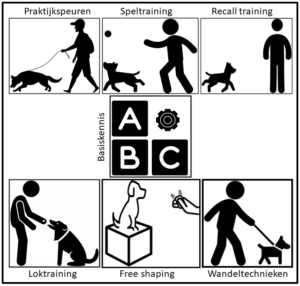
Modules
• GoBobby, gebaseerd op NePoPo® principes
• GoBobby way of working
• GoBobby 360 Training Protocol
• PoPo
• NePo
• NePoPo® uitleg (NePoPo® is een trainingsmethode van Bart en Michael Bellon)
• E-collar trainingsdriehoek
• Free shaping – Next level
• Detectie op basis van free shaping
• Loktraining
• Speltraining (praktisch)
• Speuren (praktisch)
Gebaseerd op NePoPo principes
Vraagstelling
Antwoord
 • NePoPo principes
• NePoPo principes
In NePoPo® wordt gebruik gemaakt van of gestart met Free Shaping (met clicker) om de hond actiever te maken en dit door dopamineverhogend te trainen. Onder NePoPo® hebben we ook PoPo en NePo.
Je kan NePoPo® zien als een framework dat ervoor zorgt dat je altijd terug kan vallen op een bepaalde kennis om je hond “te trainen”.
Bij GoBobby passen de NePoPo® principes grotendeels in onze manier van trainen, samen met nog andere zaken. We limiteren ons echter niet tot NePoPo® omdat dit enkel maar één methode is en elke manier van werken die je tot een methode limiteert is op zich al een beperking in je training.
We zullen dus steeds flexibel inspelen op wat verschillende trainingsmethodes te bieden hebben en implementeren wat nuttig is.
GoBobby way of working
Vraagstelling
Antwoord
• GoBobby way of working
- Weet hoe je het 360 Training Protocol dient toe te passen bij je hond?
- Creëer een gezonde relatie, gebaseerd op respect, vriendschap, vertrouwen en gehoorzaamheid.
- Creëer motivatie in de hond! Gebruik eten, spel, aandacht, free shaping etc… op een goede manier.
- Werk grondig op de primaire gehoorzaamheid op basis van beloning via PoPo en NePoPo. NePo indien nodig.
GoBobby 360 Training Protocol
Vraagstelling
Antwoord
Wat is het 360 Training Protocol?
https://gobobby.be/gobobbys-360-training-protocol/
De bedoeling van het 360 TP is om iets te hebben waarop je steeds kan terugvallen, iets dat werkbaar is, iets dat niet te theoretisch, niet te rechtlijnig en niet te compromisloos is!
Het 360 TP (Training Protocol) is praktisch en flexibel. Het geeft duidelijk aan wat de basis is maar elk punt kan je minder of meer gaan toepassen, afhankelijk van de hond zijn noden, karakter en jouw verwachtingen. Het is dus zeer flexibel en toch zeer duidelijk en toepasbaar op alle honden! Dat is dan ook precies wat de kleine en grote bubbels betekenen in de onderstaande slide van het “GoBobby’s 360 Training Protocol”. Bij de ene hond moet je op een bepaald punt meer aandacht besteden dan bij een andere hond!
Het is dus een flexibel framework waar je steeds op kan terugvallen als het gaat over gedragsmodificatie of training.

■ Wat houdt het in?
Honden leven in onze wereld, niettemin gebeurt het zeer dikwijls dat mensen geen controle hebben over hun honden en dat de hond de leefwereld bepaalt met als gevolg dat vrienden, familie of kennissen niet meer over de vloer willen of durven komen. Of het wandelen gaat moeilijk, de hond valt uit of misschien zijn er net bijna geen uitdagingen en is de hond super braaf en vriendelijk tegen iedereen en wilt men gewoon de hond zijn potentieel ontplooien etc…
Het 360 TP is een framework dat kan voldoen aan alle verwachtingen en uitdagingen, waarbij je bij de sterkere uitdagingen strakker te werk kan gaan en bij zachte, gemakkelijke honden net zeer veel kan toelaten maar de verschillende aspecten van het training protocol blijven steeds geldig en toepasbaar op elke hond.
Afhankelijk van je hond, en zijn noden/uitdagingen/karakter, kan je de basis sterker of minder sterk toepassen. Deze basis, het eerste luik, zijn de basisbehoeften, de sociale behoeften, de energy burn-off en de structuur. Dit is het allerbelangrijkste om gewenst gedrag te vormen, bij elke hond! Jong of oud, groot of klein!
Een tweede luik is de training. Daar wordt het potentieel van de hond aangepakt. Training is zeer belangrijk daar het gaat over ontplooiing en verrijking van je hond. Het geeft een hond voldoening en vult zijn noden in vele gevallen ook in. Denk maar aan speuren en detectie waar een hond zijn neus kan gebruiken of free shaping dat een mentale vermoeidheid teweeg kan brengen en in combinatie met het dagelijkse voedsel zorgt het ervoor dat je hond deze trainingsmomenten met veel plezier uitvoert! We creëren dus een actieve mindset bij de hond! De gehoorzaamheid wordt dus opgeschroefd, wat ook een voordeel kan zijn in de algemene omgang met je hond.
Een derde luik is de waardering. En zoals je leest is het een derde, en laatste luik! Waardering in de zin van extra luxe, knuffels etc… komt het best wanneer al grotendeels aan de andere zaken is voldaan en wanneer de hond betrouwbaar en controleerbaar is.
Maar waardering/appreciatie komt ook vanuit de training en de relatie die je daardoor met je hond opbouwt!
Waardering door training is zeer belangrijk en voor de hond misschien wel 1 van de belangrijkste zaken omdat het hem/haar goed doet voelen. Resultaat boeken in je training en daardoor een sterke band opbouwen met het baasje is van onschatbare waarde. Maar resultaat boeken en het gevoel hebben iets te kunnen is voor je hond ook iets van grote waarde. Het is waardering en respect voor het dier. Het is iets dat zij doen, en niet jij (niettemin doe je het wel samen)! Het geeft hen dus een goed gevoel! Een sterk gevoel van waardering!

PoPo (vrijwilligerswerk)
Vraagstelling
Antwoord
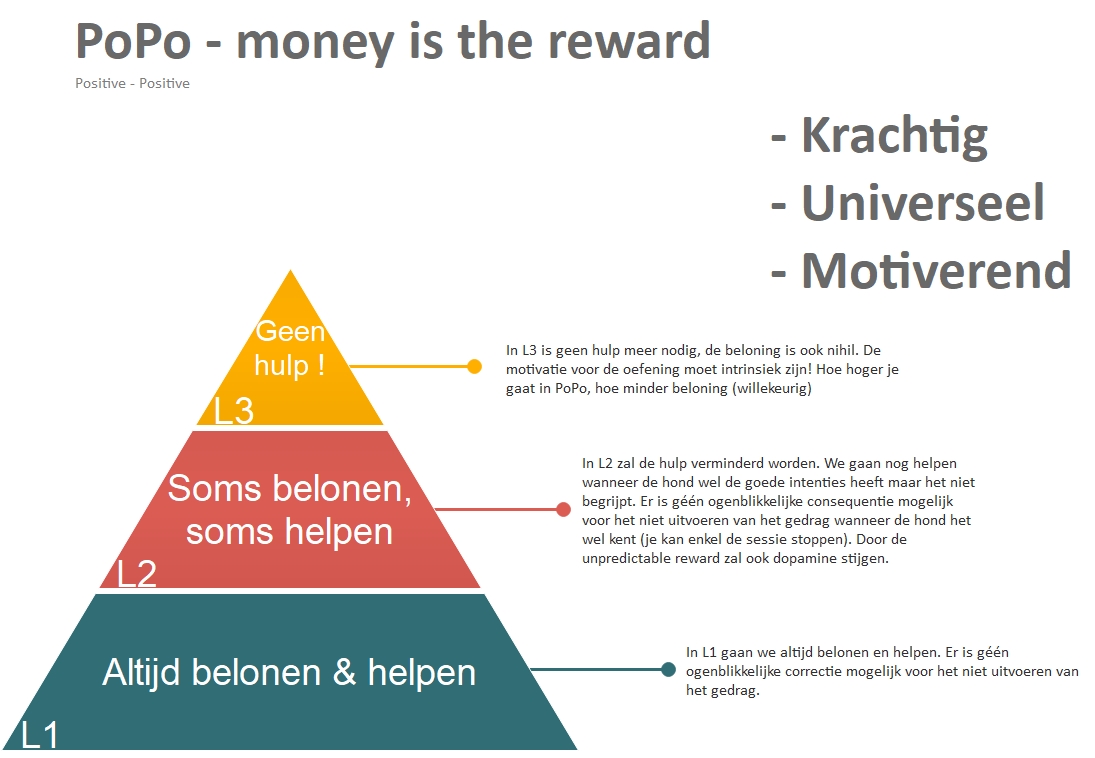
• PoPo
Bij PoPo training/shaping (positieve training) gebruiken we in principe enkel positieve impulsen & we gebruiken -in het aanleerproces- bij voorkeur voedsel (en in mindere mate spel) om de hond te belonen.
Waarom voedsel en minder spel om aan te leren?
- Eten moet je niet terugkrijgen
- De hond is in een lagere drive en leert dan gemakkelijker
Eerst moet de motivatie opgebouwd worden, hiervoor gebruiken we de clicker.
De eeste stap is dat we de clicker “OPLADEN“, figuurlijk gesproken.
Dit kan met gewoon voedsel (als de hond honger heeft en voedsel gemotiveerd is) ofwel met high-reward food. Echter om een sterk geladen clicker te hebben moet je met high reward opladen!
VOORWAARDEN voor PoPo training:
- De hond moet honger hebben (in principe bestaat puur positief dus niet want er is een negatief gevoel in de maag nl. het hongergevoel). Het hongergevoel zorgt ervoor dat de hond HANGRY is (Hungry and Angry)!
- Steriele omgeving.
- De hond moet gemotiveerd zijn! De clicker moet STERK opgeladen zijn! IGNITION!
Consequenties voor doen en niet doen?
- Consequenties voor DOEN => beloning, training gaat verder
- Consequenties voor NIET DOEN => training stoppen, “restaurant” sluit de deuren!
NePo (verplichte arbeid)
Vraagstelling
Antwoord
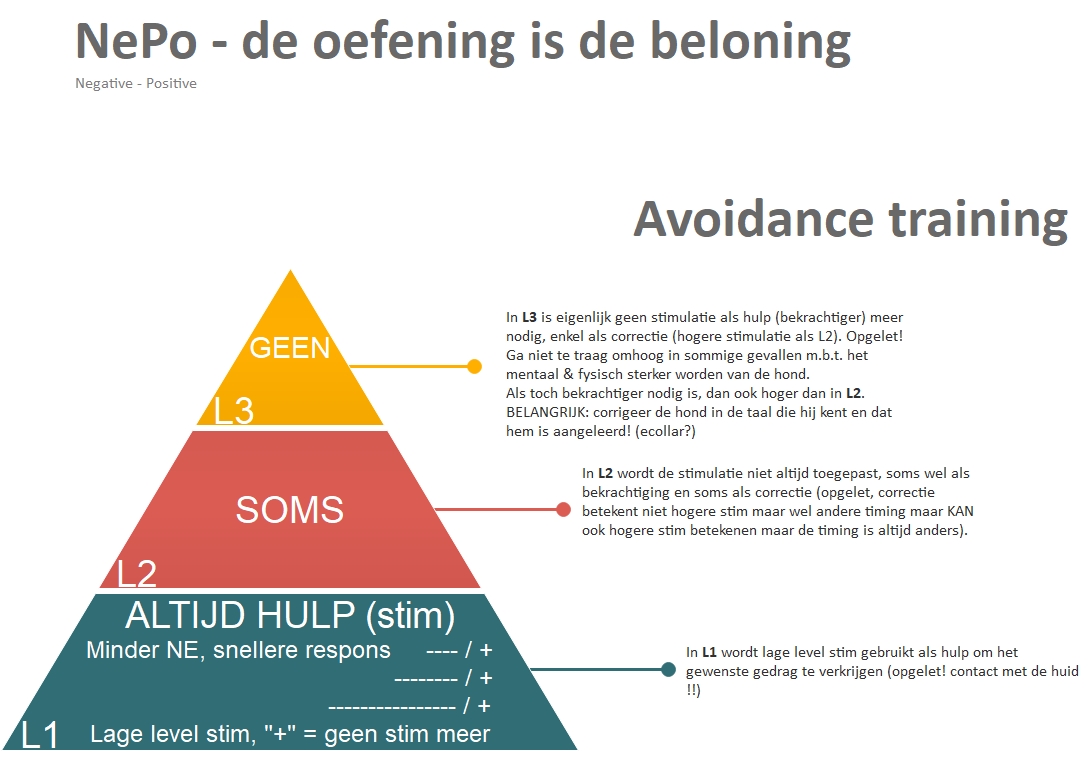
• NePo
Bij NePo training is er geen specifieke positieve beloning. De beloning is in vele gevallen de druk die weggaat. Men spreekt over “avoidance training”
NePoPo® (betaalde arbeid)
Vraagstelling
Antwoord
• NePoPo®
De nieuwe NePoPo® (versie 2) gaat over hoop en creativiteit waar het gedrag zoveel mogelijk uit de hond zelf komt. In tegenstelling tot de oude NePoPo® (versie 1) waar de hond getoond wordt wat hij moet doen.
Nepopo® training:
Old Nepopo®:
(1) LURE
(2) MOTIVATE
(3) MUST DO
(4) FLASHY
New Nepopo® (PoPo, NePo, NePoPo):
(1) FIND & SHAPE
(2) MOTIVATE
(3) MUST DO
(4) FLASHY
Ook hier moeten er consequenties zijn voor doen en niet doen?
++++• DOEN
++++• NIET DOEN wanneer de hond het kent
++++• NIET DOEN wanneer de hond het niet kent

E-collar trainingsdriehoek
Vraagstelling
Antwoord
• Hoe kunnen we de e-collar introduceren en gebruiken voor recall en het bekrachtigen van instructies?
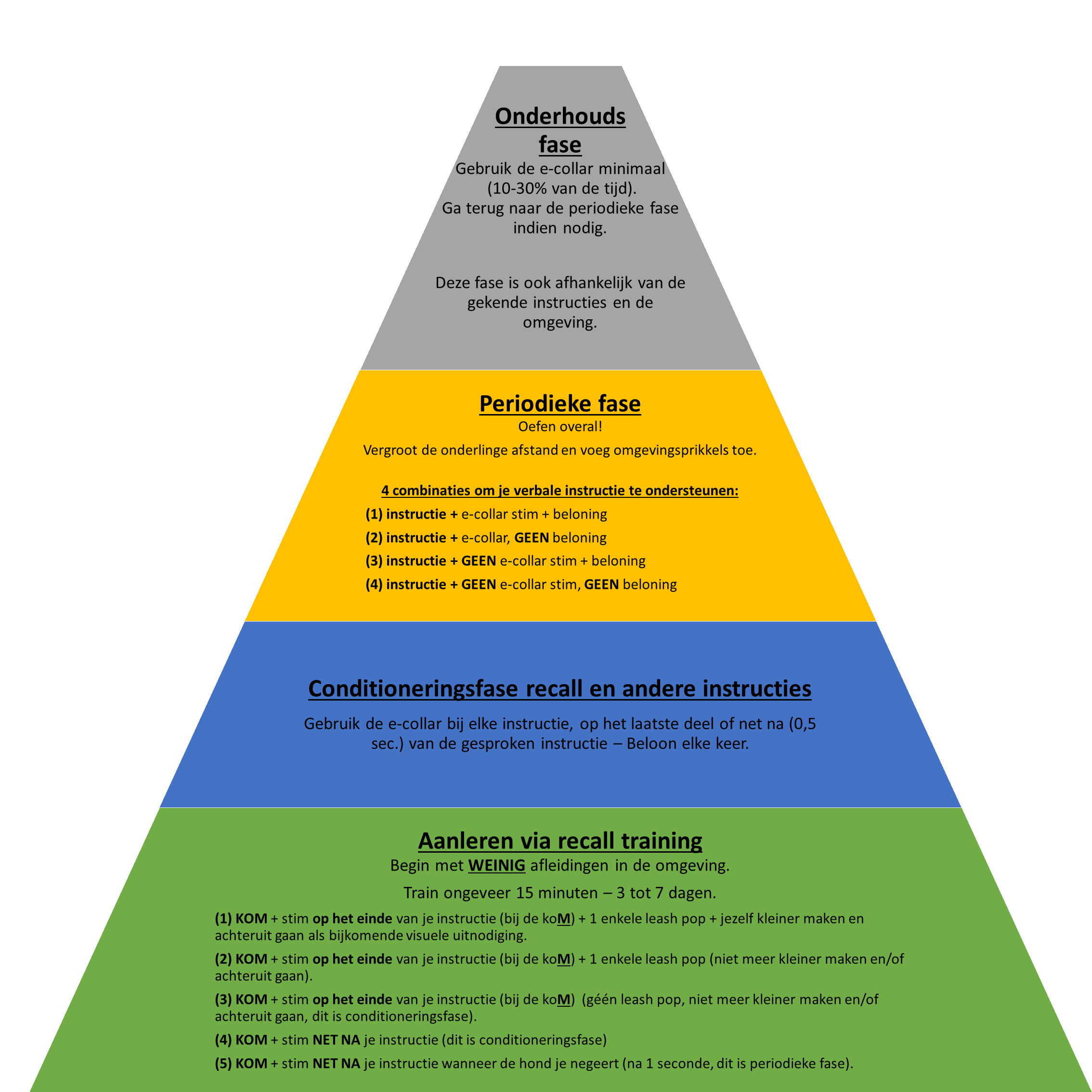
Zeer belangrijk om te weten is het verschil in timing dat je hebt bij:
- De bekrachtiging van een instructie nl. op de laatste letter van het woord, wanneer de hond de gevraagde instructie kent (contact methode – point of no return).
- Een correctie in de gehoorzaamheid nl. juist na het geven van een gekende instructie (1 a 2 seconden) wanneer de hond de gevraagde instructie niet uitvoert. De stimulatie van de correctie hoeft niet hoger te zijn dan in de contact methode maar KAN wel hoger zijn.
- Aversie nl. een hogere stimulatie die wordt gegeven op het moment dat de hond sterk ongewenst gedrag uitvoert. Aversie kan 1 bepaald gedrag stoppen maar ander gedrag teweeg brengen!
Free shaping - Next level
Vraagstelling
Antwoord
 • Wat zijn de volgende stappen met free shaping?
• Wat zijn de volgende stappen met free shaping?
Eens je hond de “stupid exercises” onder de knie heeft en goed begrijpt wat free shaping is, dan kan je praktische zaken aanleren met free shaping zoals bv.:
- Apporteren van wat dan ook
- Posities (voet, voor, tussen, rechts, etc…)
- Harnas aandoen
- Muilkorf aandoen
- Detectie
- Etc…
Detectie (gebaseerd op Free Shaping)
Vraagstelling
Antwoord
• Detectie via "the shaping game"?
Detectie op basis van free shaping is EEN methode om detectie aan te leren. Het is niet de enige methode maar het heeft wel een bepaald voordeel namelijk er moet niet met rubber (kong) of met voedsel gewerkt worden als directe beloning om de detectie aan te leren. Er wordt via free shaping met indirecte beloning gewerkt en er kan dus -indien gewenst- meteen met de doelgeur worden geoefend.
STAP 1: Inprenting
STAP 2: Zoeken
STAP 3: Zoeken met bijkomende geur als afleiding
STAP 4: Zoeken in de omgeving
STAP 5: Aanwijzen
STAP 6: Zoeken en aanwijzen
STAP 7: Zoeken met aanwijzingen van de begeleider
STAP 8: Free run
Deze module is online te volgen via Https://k9training.be
Speltraining (schakelen, verhogen of verlagen van drift in combinatie met gehoorzaamheid)
Vraagstelling
Antwoord
 • Deze module is praktisch
• Deze module is praktisch
Deze module is praktisch
Loktraining
Vraagstelling
Antwoord
 • Via het jachtspel?
• Via het jachtspel?
Loktraining algemeen:
Luring (lok-training) is een effectieve manier om je hond nieuwe posities aan te leren. Het is gemakkelijk, een actieve training, honden vinden het leuk en je kan vrij makkelijk en snel nieuw gedrag aanleren op deze manier. Dit type training houdt simpelweg in dat je een voedselbeloning gebruikt om de hond naar de gewenste positie of gedrag te leiden (directe beloning) en na verloop van tijd die voedselbeloning gaat faden eens de hond de volledige uitvoering kent. Dit is een gemakkelijke methode om snel iets aan te leren, indien de hond gemotiveerd is. Iets dat ALTIJD op dezelfde manier uitgevoerd moet worden (zit, voet, lig etc...)!
■ De aandachtspunten zijn:
- Dat je hond in het begin niet zelf nadenkt (maar dat later wel zal moeten doen wanneer het eten uitgefaseerd wordt).
- Dat je het lokken en sturen met het eten sowieso zal moeten uitfaseren (bij shaping niet noodzakelijk).
- Dat je hond associaties maakt die misschien niet gewenst zijn.
- Dat je hond misschien enkel zal werken voor het eten.
- Dat je gemakkelijker kan valsspelen dan bij free shaping.
■ Verloop van zero to hero met betrekking to loktraining:
Wanneer we iets nieuws aanleren aan de hond, dan gaat dit volgens verschillende fases:
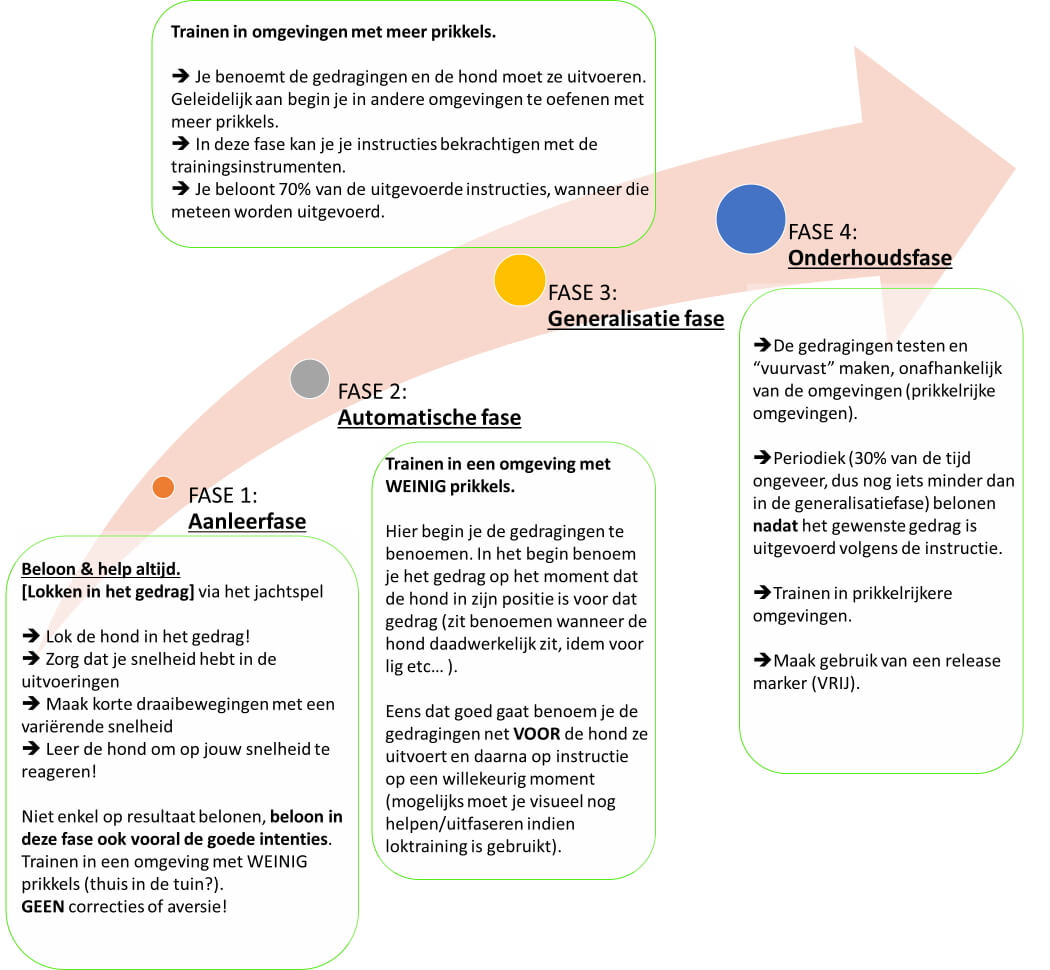
Opgelet:
“Lokken met voedsel” is een bepaald gedrag sturen (vb. “ZIT” voedsel gaat omhoog tot de hond gaat zitten). Dit wordt gebruikt om iets nieuw aan te leren.
Lokken met voedsel wordt gebruikt in Fase 1 en Fase 2 (op het einde van fase 2 al minder dan aan het begin van fase 2).
“Beloning met voedsel” is anders dan “lokken met voedsel” in die zin dat voedsel bij “beloning met voedsel” enkel gegeven wordt wanneer het gevraagde gedrag al uitgevoerd is.
“Omkopen met voedsel” is iets wat je ook zeer regelmatig ziet. Honden die wel weten wat er van hen wordt verwacht maar het enkel nog maar gaan uitvoeren wanneer het baasje met eten zwaait.
If you don’t use it, you lose it! Af en toe moet je de aanleerfase en automatische fase opnieuw oefenen, enkel maar om de “muscle memory” van de hond te trainen.
Posities:
Voor het aanleren van de posities kunnen we loktraining gebruiken waar je de oefeningen afzonderlijk doet (voet/zit/lig) ofwel kan je alles samen oefenen via het jachtspel (https://k9training.be).
Een aantal posities kunnen echter ook via free shaping worden aangeleerd. Voorbeelden hiervan zijn te vinden op de online training https://k9training.be
Er is niet 1 methode beter dan de andere hiervoor want de hond moet niet specifiek inventief zijn om naar de voet te komen. In een experiment met 2 honden (Mechelse herder en een Dobermann) werd de ene hond via free shaping geleerd om aan de voet te komen en de andere via loktraining. Het resultaat was nagenoeg hetzelfde.